
In the realm of legal technology, the integration of Large Language Models (LLMs) has been a game-changer for analyzing and understanding complex legal documents. These innovative AI tools have propelled the capabilities of question-answering systems to new heights. However, when it comes to dissecting intricate legal documents using traditional vector-similarity based Retrieval-Augmented Generation (RAG) architectures, there are notable limitations.
Consider the task of extracting detailed information from a complex will document, filled with specific bequests to various beneficiaries, conditions based on future events, and contingent executors. A vector-similarity search RAG architecture (as I discussed in previous posts) might struggle here, primarily because it relies on identifying the closest match from a corpus of text based on keyword similarity. For instance, if asked, “Who inherits the estate if the primary beneficiary predeceases the testator?” the system might falter, unable to piece together the conditional logic across disconnected text segments that don’t share direct keyword similarities.
In contrast, a graph-based approach provides a more nuanced understanding. By first converting the will document into a knowledge graph, each individual (be it beneficiary, executor, or trustee), asset, and conditional event is represented as an interconnected node. This visual map allows for a dynamic representation of relationships and hierarchies, highlighting how certain conditions (like the predeceasing of a beneficiary) affect the flow of assets.
Utilizing this advanced method, an LLM-based chatbot connected to the knowledge graph can now accurately and swiftly navigate these complex relationships. Querying the aforementioned question, the chatbot would trace the relationships and conditions outlined in the graph, identifying the secondary beneficiaries or contingent plans detailed for such a scenario, providing a precise answer that a vector-similarity search simply couldn’t muster.
Beyond improved accuracy and depth in legal document analysis, the graph-based architecture offers additional benefits, notably in personalized legal advice and predictive analytics. By understanding the intricate web of relationships and conditions in documents like wills or trusts, LLM-based systems can generate insights on potential legal implications, offer tailored advice, or even forecast future legal needs – all by querying the knowledge graph.
In the image attached to this post is my work-in-progress of translating a trust document into a graph representation. Blue nodes represent people. Purple nodes represents major events. Orange nodes represent roles and green nodes represent assets.
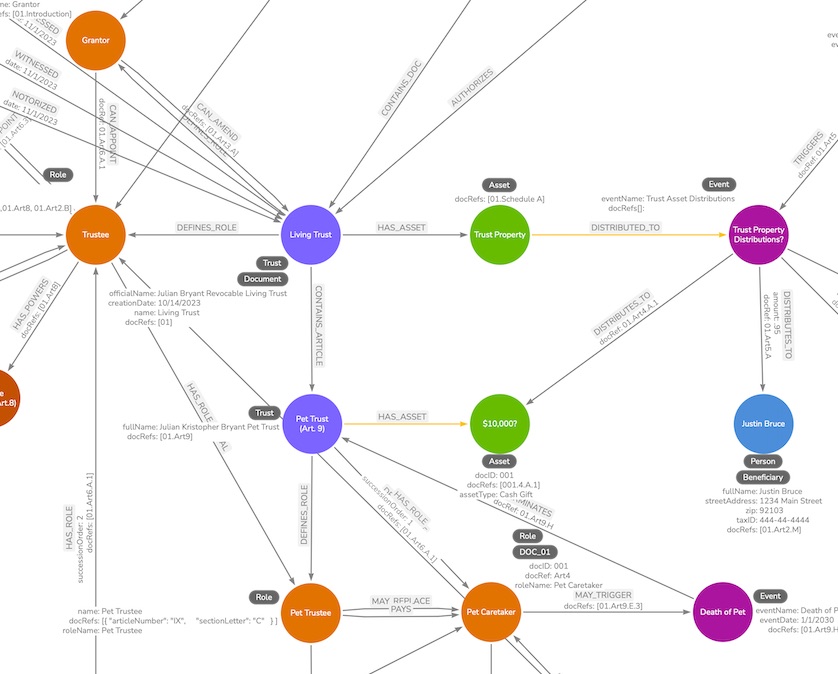
Between each node is an arrow describing the relationship that exists between the nodes. So while the diagram looks complicated, if you start with any given node and follow the relationships out you can understand the architecture of the trust. These graph databases excel at capturing the complicated relationships between entities, but are not the best for storing the actual text of the document, so you’ll see in many places there are references to the applicable sections of the underlying document.
In summation, while vector-similarity RAG architectures have paved the way for AI in legal tech, their limitations in handling complex legal documents underscore the need for innovation. The marriage of graph databases with LLMs represents not just an evolution, but a revolution in how we process, understand, and utilize legal texts, redefining efficiency and precision in legal operations.